

前言:近期“ASICBoost专利门”事件轰动整个币圈,并且影响比特币的未来。整个专利技术涉及比特币打包挖矿的低层,可能较少有人能弄懂。本文在参考大量文献后,尝试以通俗易懂的方式,介绍整个挖矿技术知识。任何支持判断要基于技术进行客观判断,会比基于一些人的主观言论判断要靠谱很多。
第一篇、哈希算法HASH
哈希算法,又称为散列函数,是将任意长度的二进制值映射为较短的固定长度的二进制值,这个小的二进制值称为哈希值。
为了方便理解,大家可以想一下较熟悉的WinRAR压缩软件,无轮是只有一个原始文件,还是好几个原始文件,都可以压缩成一个RAR文件。当任何一个原始文件有任何变动时,重新压缩生成的这个RAR文件就会发生变动,而不再是之前的文件。
而哈希算法有点类似,但其处理的对象不是文件,而是字串。将任意长度原始字串“压缩”成一个字串即Hash字串。原始字串任何一点点微小的变化都会引起Hash的变化。与RAR的不同之处是,通过Hash结果是不可以“解压”还原成原始字串的。
哈希算法有很多很多种,典型的哈希算法有MD2、MD4、MD5 、 SHA-1、SHA-2、SHA-256、SHA-512、SHA-3、RIPEMD-160和SCRYPT算法(莱特币和狗狗币使用)等等。在比特币中大量采用的是SHA256算法,仅仅在从公钥生成币地址时还另外用过RIPEMD160算法,其它地方用到Hash时一般就是用SHA256算法。其特点如下图所示将任何字串转变生成256位随机的0或1。

第二篇、矿机挖矿的底层
其实矿机的底层到底在做什么是较好理解的,就是不断地改变原始数据,来不断地求算SHA256算法下的Hash值,当满足一定条件时成功。
2.1满足什么样的条件时成功?
看近期的区块461,228的块哈希值实例。
000000000000000001f682adc333ebb751e63b204c8f8aa7b595e11394d5a154
前17个都是零,另外后面的数也要小于一定的数,那么才满足条件。而这些哈希值结果是随机的,能做的这么规律,只能是不断地更换原文内容不断地进行尝试,在大量的随机结果中来筛选满足难度条件的。难度并非固定的,根据全网算力挖块的情况,每挖出来2016个区块(约两周时间2016/6/24=14)就调整一次难度。若挖完2016区块所用的时间短于两周,那就提高难度;而若长于两周,那就降低难度。
2.2原始数据是些什么数据?
并非对整个区块内容取Hash值,而是仅仅只对80字节大小的区块头,进行SHA256算法。这80字节具体分为六个部分。
1)版本号Version:4字节,进行投票时变
按目前的BIP9升级规范,版本号是用于投票区块自己支持的分叉升级方案,如若支持SW可版本号为0×20000002具体可看下面这个文章:
2)前区块Hash:32字节,有新区块时变
这是将区块串成区块链的关键,表示这个区块是在哪个区块的基础之上进行挖矿而挖到的。当比特全网出现合法的新区块后,要及时替换上新区块的Hash,否则就算挖出来也可能被孤立。
3)交易树根MerkleRoot:32字节,交易变时变
本应该是所有交易都进行Hash的,但是计算量太大,于是将所有交易用Merkle Root Hash的方法,将所有交易Hash合并成一个32字节的Hash数据。它能代表所有交易,任何交易的任何细小变动都会引起MerkleRoot的变动。这个后面还有更多讨论和图。
4)时间戳TimeStamp:4字节,当前时间微变
最好写当前时间,但不是很严格,允许有一定的时间偏差,但不能偏差太大,偏差太大会被区块孤立的。因为不严格,有时下个区块比它的上个区块的时间戳时间还早,这是有可能的,但真实的诞生时间当然是先有上个区块,才会有下个区块。
5)当前难度值Bits:4字节,每两周左右变一次
由全网算力决定,每2016个区块重新调整,调整算法固定,就是说在调整时,大家都可以根据历史数据自己计算出来,而不是由谁指定。怎么用四个字节表示难度呢?有点类似于天文数字的科学计数法,第一个字节V1代表右移的位数,用剩下三字节V3表示具体的有效数据。
F(nBits)=V3 * 2^(8*(V1-3) )
6)随机数Nonce:4字节,随时可变
这个是给矿工挖矿时自己调整用的,以便能找到合适的值让区块头的Hash结果能满足难度需求。这个参数估计中本聪有点失误,设计小了,仅仅4字节,CPU挖矿时代够用,但显卡GPU时代,就有点不够用了,几秒的时间就能全部的Nonce都全试了一次了。不过可以微调上面的时间戳TimeStamp,调一次就可以再挖几秒,勉强够用。然而进入专业矿机矿池时代,Nonce就远远不够用了,由于各字段一般都有较明确有固定含义不能轻易动,于是转向32字节的交易树根MerkleRoot。
第三篇、矿工与矿池的互动
若在很早期完全矿工自己独立挖矿即可,然而随着挖矿难度的提升个人矿工已经无法与矿池模式竞争。看看下图近期7天的区块情况。绝大多的区块,都是由矿池挖出来的。矿池与矿工之间有明确的分工合作。
3.1矿池为矿工提供的挖矿服务
收集比特交易是矿池上完成的,矿池需要运行全节点,而矿工却不需要。如下图蓝线指示,矿池会由待打包的交易生成那些黑点,然后时常发给矿工。另外构造一个基本coinbase交易,也发给矿工。理论上矿池给矿工的coinbase交易内容能维持较长时间不变动。但SW隔离严证实施后,每当有交易顺序或交易内容调整时,都需要变动coinbase。还有就是矿池要提供除了MerklerRoot和Nonce之外的区块头数据。
3.2矿工为矿池提供的算力贡献
矿工收到从矿池发过来的信息后,第一步是计算红点,完善coinbase交易一般是加个随机数即可完善好,然后对coinbase交易进行SHA256的Hash计算。第二步是计算绿点,将coinbase的结果,再依次和下图中的黑点逐一合并得出上一层的Hash,最终得到最上面的交易树根MerklerRoot。第三步是计算区块头Hash,有了MerklerRoot后,结合矿池提供的区块头数据,再加个随机变动的Nonce就可以形成完整区块头,用其计算Hash。当Nonce完全遍历一遍和足够变动时间戳后,正常一般是回到第一步更换一个随机数来重新完善coinbase交易,进而第二步中MerklerRoot值最终将不一样。而ASICBoost可能是调换交易顺序而更新MerklerRoot。第四步是提交成功的Share计算结果,并非要满足全网的难度般,只要满足矿池设的挖矿难度就可以提交了,一般提交给矿池自己的矿工ID和任务ID,coinbase的随机数和区块头的时间戳TimeStamp及随机数Nonce。矿池在收到后及时进行验证,若满足则记一份功劳贡献,同时看看是否满足全网的难度要求,若满足则广播发布出去,从而挖到新块,且按记录的功劳Share数量分配给各矿工应有的币量。
第四篇、专利ASICBoost优化
若您看到这里了还能继续较清晰,说明您智商很高呀,但并非矿业智慧的终结,还有更加聪明的人设计了ASICBoost专利,理论可提升30%,但是需要硬件和软件,尤其矿机和矿池的默契配合。
具体专利细节还不很清楚。但感谢@拿铁大 的微博,已经给了较好的内容描述。本文引用其中的一部分来进行说明。
根据目前了解,简单说,其就是利用了SHA256算法的内部计算规则,先64字节一组,然后再4个字节一个组。而ASICBoost专利,应该就是用交换交易位置的方式,不必修改coinbase,来快速得到很多相同的末尾4字节的MerklerRoot,从而硬件可加速优化计算区块头两次SHA256的哈希值,即SHA256( SHA256( BlockHeader ))的速度。
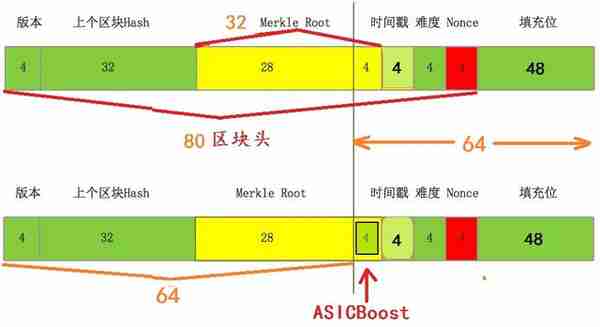
在计算这个区块头的SHA256时,我们需要先用固定的填充位补齐为128字节,之后SHA256会64字节一组去处理,可以简单认为是 F ( F(SHA256规范的初始值,前半部分), 后半部分)。F又需要对这64字节先按4字节一组拆分,进行64轮计算。结合上图,我们不难发现,Merkle Root的前28个字节和后4个字节被分开了,在修改Nonce过程中,前半部分是不变的,而后半部分的前12个字节也是不变的。因此目前几乎所有的芯片都已经做了这两个优化,即前半部分的处理结果(getwork中的midstate)和后半部分的前3轮结果(midstate3)。这样的优化效果是 (61/64+1)/3 = 65.1%,提升了34.9%
Merkle Root在图上显得很尴尬,如果中本聪设计的时候Version变成第三个字段该多好(就是说把Version放在MerkleRoot的后面)。这样后半段的前4个字节就固定了,如果我们对于时间戳要求不那么高,前12个字节可以完全固定下来了。对于芯片来说可以节省更多的计算,也可以去掉对应的一些电路。ASICBoost将这个脑洞往实践推了一步:我们去构建一组后4个字节相同的Merkle Root。
这样问题就变成能不能高效找到后缀一样的Merkle Root?效率提升有多大?ASICBoost的白皮书提到有很高效的方法,并且给出了一张表:
ASICBoost白皮书的Merkle Root碰撞数量对效率影响ASICBoost白皮书的Merkle Root碰撞数量对效率影响。(表格的意思是若找到五个相同后4字节的Merkle Root那么效率能提升20%)
这里问题的本质是一个32位的哈希碰撞,根据“生日悖论”,找到一组碰撞需要的尝试次数其实并不多,我们只需要77000次就有50%概率找到两个后缀相同的Merkle Root。当然对于一台矿机来说,仅仅2个是远远不够的,如果是矿场的话应该需要配备专门的硬件去产生足够的任务。尝试新的Merkle Root通常有两种方法:
方法一:修改Coinbase交易。这个方法似乎最简单而且隐蔽,但是白皮书认为不够高效;
方法二:交换任意交易的顺序。白皮书只举例了方法2,其他方法并未给出。注意无论是1和2,新的Merkle Root并不需要从下而上全部计算。
第五篇、与隔离验证SW关系
隔离验证SW:Segregated Witness是将签名隔离出来放后面,实现约1.7MB的链上软扩容效果。另外LN闪电网络,侧链技术等很多币技术都在等待SW的激活。为何ASICBoost专利的获利方会阻碍SW呢?
5.1ASICBoost专利,需要交换交易的顺序
以便能快速产生大量的Merkle Root,并且从中选择出较多的最后4字节相同的Merkle Root,然后发给矿工。这个主要是在矿池的工作,因此仅仅有支持ASICBoost的矿机,若没有矿池配合是不行的。另外矿机收到这些最后4字节相同的Merkle Root需要矿机硬件配合,能进行特殊的硬件存储优化。因此仅仅只有支持ASICBoost的矿池,没有ASICBoost的矿机也不行。并且我觉得并不会在区块链上留下太明细的使用ASICBoost的痕迹,除了交易顺序有点乱,而本来就不整齐,另外有可能空块率,比其它矿池要高点,因为只有coinbase交易时,寻找最后4字节相同的Merkle Root会更快些。
5.2ASICBoost专利,在SW隔离验证实施后效率降低
因为将无法再轻易交换任意交易的顺序。因为SW将会有个Witness Merkle Root要写入coinbase交易的OP_return输出。也就是说,交换交易顺序,之前是不影响coinbase,而SW隔离验证实施后,交换交易顺序,那么Witness Merkle Root可能就要跟随变化,进而coinbase变化。最终将还不如直接按上面方法一直接修改coinbase来找最后4字节相同的Merkle Root更方便些。因此SW隔离验证实施,并不能完全阻止ASICBoost专利的实施,但是会降低其效率,进而减少ASICBoost专利实施人的利益。
另外近期最新的提出来的EXTBLK延展区块方案,之所以几乎立刻被其接纳支持。在于EXTBLK延展区块虽然也是写入coinbase交易的OP_return输出。但是EXTBLK中的交易与主链交易较独立,交换主链的交易的顺序,应该是不会影响EXTBLK Merkle Root的。
为自己的利益而反对某种方案,可表示理解,但是应该实话实说,而不是用其它的理由(说SW代码太复杂改动较多不安全,却不支持LTC先SW来帮测试代码),也不能去支持对立的不靠谱的版本(BU那么差短期内数个Bug,且EC涌现共识更复杂却去强力支持,只因为BU不影响ASICBoost)。
呼吁ASICBoost持有者,要多多为整个币圈着想。不能为了一时利益而损坏整个币圈的利益,还有百余个币应用在等待着SW激活呢。并且并不是ASICBoost专利完全失效,仅仅是效率降低而已,通过调节coinbase中的随机数是可以继续使用ASICBoost专利的。以后会变成两步,先是一步是矿池运行的Merkle Root矿机,计算大量后4字节相同的Merkle Root。然后一步是后缀同Merkle Root数据给支持ASICBoost专利的比特矿机。
专利技术内容公开后,也就没有必要偷偷摸摸了。整个矿业可以集体进入下一个阶段。各大矿池未来不再仅仅只是拼网速和分配手续费比例,更加拼矿池的Merkle Root矿机能力。
那么说到现在,这事和隔离见证有什么关系?隔离见证引入了”witness tx id”,交易在原有ID之外有了另一个新的ID,即用新的交易序列化格式(不包含签名部分)得到的交易哈希。相应的,我们也有了一个新的Witness Merkle Tree,以及Witness Merkle Root。由于软分叉实现,我们不能替换现有的Merkle Root,而是在Coinbase交易中增加一个OP_Return的输出,写入这个“WMR”。而这也导致对任何交易或者交易顺序的改动,我们都要从下而上重新计算“WMR”,大大降低了伐木效率。
好啊,知道你们为什么要阻止隔离见证了,原来就是要偷着用ASICBoost啊,你们不仅会阻止隔离见证,还会阻止一切比特币的进步。
打住吧。。。。
可以使用ASICBoost+反对隔离见证 不等于 为了ASICBoost反对隔离见证。
你看到了两个事物同时存在,就觉得其中一个事物是另一个的起因。你的错误在于,同时存在的两个事物未必有因果关系。
